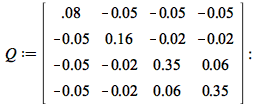Maple provides a collection of commands for numerically solving optimization problems, which involve finding the minimum or maximum of an objective function, possibly subject to constraints. The Optimization package enables you to solve linear programs (LPs), quadratic programs (QPs), nonlinear programs (NLPs), and both linear and nonlinear least-squares problems. Both constrained and unconstrained problems are accepted, and the package accepts a wide range of input formats.
You can also use Maple to perform global optimization. For more details, see Maple Global Optimization Toolbox.

Maple
Leistungsfähige intuitive Mathematiksoftware
• Maple für Akademiker • Maple für Studenten • Maple Learn • Maple Calculator App • Maple für Industrie und Behörden • Maple for Individuals
Erweiterungen für Maple
• Books & Studienführer • Maple Toolboxen • MapleNet • Kostenloser Maple-Player
Math Success Platform
Mathe-Erfolg im Zeitalter der KI
Maple Flow
Engineering calculations & documentation
• Maple Flow • Maple Flow Migration Assistant

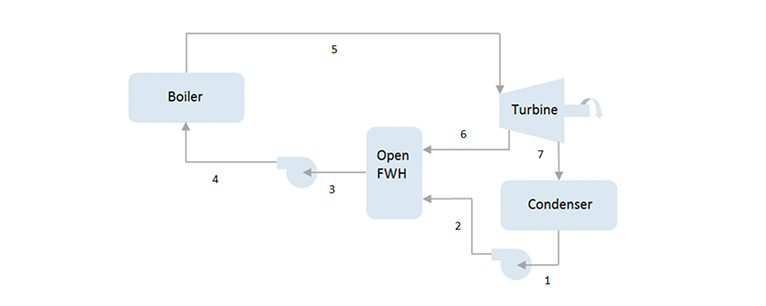
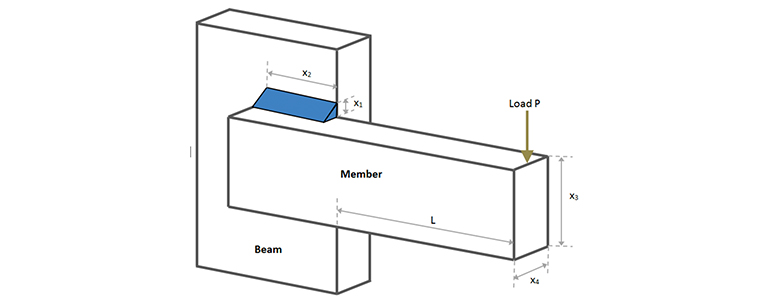



![Var(Sum(`*`(x[i], `*`(R[i])), i = 1 .. n))](/products/maple/features/images/optimization/optimization_examples[1]_43.gif) , which can be shown to be equal to
, which can be shown to be equal to